应用工程统计学基础
基本概念
随机变量 是指变量的值无法预先确定,仅以一定的可能性(概率)取值的量。
- 连续型随机变量: 对于随机变量X,若存在一个非负的可积函数f(x),使得对任意实数x,有 ,则称X为连续性随机变量。
- 离散型随机变量: 取值只有有限个或可列无穷个。
概率 是出现某个值的可能性。
连续型随机变量
对于连续型变量,它的值是无限的,于是对于某个点来讲,它的概率是零,即P(X=x)=0
那怎样定义概率?
-
概率密度函数: Probability Density Function (pdf)
-
累积分布函数: Cumulative Distribution Function (cdf)
平均值和方差 Mean and Variance
平均值 (期望值):
方差:
标准方差为
重要的连续型随机变量分布:
正态(Normal)分布 又名高斯(Gaussian)分布 Normal Distribution
为什么重要: 中心极限定理 The Central Limit Theorem*
怎么来的: 正态分布的前世今生
表示成:
它的概率密度函数为:
标准正态分布 Standard Normal Distribution
当一个正态分布变量满足, 我们把它称为标准正态分布变量,记做 ‘Z’ 。
- 它的概率密度函数为:
- 它的累积分布函数为:
如果X是一个普通的正态分布变量,,我们可以将其 转化 为标准正态分布变量:
所以:
然后我们就可以使用标准正态分布表查询概率了,表上面是它的累积分布函数的值。
离散型随机变量
取值只有有限个或可列无穷个,比如投骰子的点数,调查的人数。
定义概率
-
概率质量函数 Probability Mass Function: 离散随机变量在各特定取值上的概率
-
累积分布函数: Cumulative Distribution Function
平均值和方差 Mean and Variance
平均值 (期望值):
方差:
标准方差为
重要的离散分布:
二项分布 Binomial Distribution 又名贝努利(Bernoulli)分布
只有两种可能结果(0或1,成功或失败)的试验非常频繁,我们将它们称为贝努利试验。
基于假设: 1. 每一次试验都是独立的,不会受到其他试验的影响。 2. 试验为某一值的概率是恒定的。
比如著名的抛硬币实验,结果只有正面和反面,每一次投硬币都是独立的,为正面和反面的概率都恒定是0.5。
n次二项分布试验的结果中某一值出现的个数的几率
中心极限定理 The Central Limit Theorem
在一定条件下,大量独立随机变量的平均数是以正态分布为极限的。即你多次从总体中拿样本,只要样本数量n足够大,分别计算它们的均值,这些均值的分布趋于正态分布。。推导
有趣的是: 无论是属于什么分布的随机变量,都满足这个定理。
于是我们得到关于样本均值的标准正态分布函数:
(后面会经常用到这个公式)
单样本情况
统计推断
统计在研究现象的总体数量关系时,需要了解的总体对象的范围往往是很大的,有时甚至是无限的,而由于经费、时间和精力等各种原因,以致有时在客观上只能从中观察部分单位或有限单位进行计算和分析,我们要根据样本数据来推断总体数量特征。
统计推断分为两个部分: 参数估计和假设检验
参数估计
-
一般用样本均值估计总体均值
样本均值函数: -
一般用样本方差估计总体方差
样本方差:
总体方差:
点估计
| 未知参数 | 统计 | 点估计 |
|---|---|---|
假设检验
基本思想是小概率反证思想。小概率事件(P<0.01或P<0.05)在一次试验中基本上不会发生。
即我们对总体的某个统计量(一般为均值)提出零假设H0,然后求得在这个零假设前提下当前样本的发生概率,如果概率非常小,则认为我们的零假设不对,拒绝我们的零假设H0。
具体步骤结合例子为下面7步:
例子: 我们想知道一种固体推进器的线性燃烧速率是否为50cm/s,前提假设总体方差已知为2.5。于是我们做了试验,得到一组样本数据,然后我们进行假设检验:
- 将问题提炼为统计问题:
- 提出零假设 Null hypothesis,
- 提出备择假设 Alternative hypothesis,
- 确立检验统计量:
- 定义拒绝 的拒绝域:
- 根据样本,计算检验统计量的值:
- 判断是否拒绝:
当然假设验证的结论是根据概率得出来的,它会产生两类错误:
| 实际情况 | |||
| H0正确 | H0错误 | ||
| 研究结论 | 拒绝H0 | I类错误 | 正确 |
| 没有拒绝H0 | 正确 | II类错误 | |
- I类错误
这类错误危害较大,因为拒绝假设为强结论,如果后续研究、应用基于这个结论,危害不可估量。
产生原因:- 样本中极端数据?
- 样本太小了?
- 定义的拒绝域太大了?
在这个情况下,我们引入显著性水平(Significant Level)的概念, ,即发生I类错误的概率,来帮助我们理解拒绝域,可以如本例先给出拒绝域来求得显著性水平,也可以预定义显著性水平来求得拒绝域,都是人为主观预定的,与实际样本数据没有绝对关系。
在上例中,由于中心极限定理,样本均值服从正态分布,于是我们可以得到显著性水平等式:
(当样本数量n变大,样本均值们所遵从的正态分布的方差变小,均值们会更向中间集中,由同样的拒绝域而求得的显著性水平会变小,即发生I类错误的可能性变小)
- II类错误
这类错误发生比较普遍,H0错误的情况下,没有拒绝H0。主要是实验设计上面的问题。此类错误危害较小,因为结果为不能拒绝H0为弱结论,并不等于H0正确,只是我们没有足够证据证明H0不正确。 我们引入概念。
比如H0错误,总体均值其实是52,这就相当于在总体均值为52的情况下,求样本均值落在48.5到51.5区间的概率, 即
但是当
在真正的总体均值距离H0假设的总体均值比较近的时候,我们有很大的几率不会拒绝H0。
P值(P-Value)
现在我们有了样本数据,我们可以求得假设H0正确的概率,即为P值。
在上例中:求得样本均值至少51.8时,然后我们计算H0:正确的概率P值。
因为这是一个Two-sided P-value问题, 这只是一边的情况,因为正态分布是对称的,于是我们判断。于是当我们选择的时候,拒绝零假设H0。
One-sided还是Two-sided取决于备择假设,备择假设取决于实际问题。一般来讲我们设计假设验证都是想要去拒绝零假设H0,我们关心的其实是备择假设H1,不等于,还是大于或者小于。比如检验新配方是否有改良,数据越高越好时,我们只关心H1:。
零假设H0:
样本均值分布:
| 备择假设 | P值 | 假设拒绝条件 |
|---|---|---|
均值的置信区间 Confidence Interval on the Mean
有时候,根据样本均值,光给出点估计是不够的,我们想要的一个区间,比如真实值有95%的概率落在[48,52]。
置信区间体现了这个参数的真实值有一定概率落在测量结果的周围的程度。比如一个Two-sided区间
其中为置信系数confidence coefficient,即真实值落在[L,H]范围内的概率。
也有单边One-sided区间:
当我们拿到一个样本,在给定显著性水平(Significant Level)以后,我们就可以通过计算求得置信区间 Confidence Interval的范围。这个范围由样本数据和显著性水平决定,和假设检验H0无关。当我们求得置信区间的值,根据H0是否落在置信区间,可以判断是否拒绝假设检验H0。
方差已知,或者方差未知样本数量大于30的情况下,公式:
方差未知,样本数量小于30的情况下,公式:
单个样本问题主要有以下几种情况
在总体方差已知的情况下,推测总体均值
以上的例子就是基于方差已知的情况。对假设的总体方差进行z-test。
这种情况现实问题中比较少见。
根据中心极限定理,样本均值遵从标准正态分布。
z-test
根据中心极限定理: 服从标准正态分布
验证:
测试的统计量:
检验方式:1.P值 2.给定显著性水平 3.置信区间
置信区间 CI公式:
在总体方差未知的情况下,推测总体均值
总体方差未知的情况下,如果样本数量大于30,S和的差别比较小,根据中心极限定理均值也更趋向于正态分布。我们可以将样本方差S来近似总体方差直接用于z-test。
可是当样本数量小于30,z-test的误差会比较大。在总体分布为正态分布时,我们可以用到t分布,进行t-test。
t分布:根据小样本来估计呈正态分布且方差未知的总体的均值。
t分布的概率密度函数为:。
使用中需要查询t分布临界值表,用自由度k和显著性水平来查询拒绝H0的样本均值临界值。
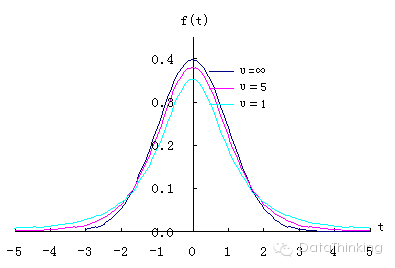
t分布和正态分布的关系如下图:当自由度k变大,即样本数量变大时,t分布越来越向中间集中,越来越靠近正态z分布。正态分布是t分布的极限状态。
t-test
当 服从t分布
验证:
测试的统计量:
服从t分布
检验方式:1.P值 2.给定显著性水平 3.置信区间
置信区间 CI公式:
变量呈正态分布情况下,推测总体方差
首先,变量必须是符合正态分布的。
定理:若n个相互独立的随机变量服从标准正态分布,未知均值,未知方差,则:
服从自由度为n-1的卡方分布(chi-square distribution)。
chi-square distribution
因为变量呈正态分布,所以 服从卡方分布
验证:
测试的统计量:
检验方式:1.P值 2.给定显著性水平 3.置信区间
置信区间 CI公式:
二项分布情况下,推测比例
z-test
根据中心极限定理,
验证:
测试的统计量:
检验方式:1.P值 2.给定显著性水平 3.置信区间
置信区间 CI公式:
推测总体分布
- Probability plotting 概率图(主要用来判断正态分布,对数正态分布,威布尔分布)
一般我们可以用样本数据画一个正态概率图。如果这组实数服从正态分布,正态概率图将是一条直线。
from scipy import stats import matplotlib.pyplot as plt # generate random numbers x = stats.norm.rvs(size=50) # probability plot res = stats.probplot(x, plot=plt) - Chi-Square Goodness of Fit Test 卡方检验
双样本情况
在总体方差已知的情况下,推测两个分布均值的差别
两个分布的总体均值的差别为:,因为中心极限定理两个样本均值分别服从正态分布,有意思的是,两个正态分布的差值是另外一个正态分布(推导)均值为,方差为。
即 服从标准正态分布,于是我们可以使用Two-sample z-test了。
Two-sample z-test
基于中心极限定理和两正态分布的和/差是另外一个正态分布
验证:
测试的统计量:
在总体方差未知的情况下,推测两个分布均值的差别
若样本数量n1,n2大于30,则使用样本方差近似总体方差,使用上面的Two-sample z-test。 若样本数量较少,我们要求总体分布为正态分布,然后用t分布求解验证假设和置信区间。 然后根据方差分两种情况:
-
两个方差相等,使用Pooled t-Test
验证:
测试的统计量: t分布的自由度:n1+n2-2。
其中, -
两个方差不等,使用Welch’s t-Test
验证:
测试的统计量:
t分布的自由度公式比较复杂:
配对样本t检验 Paired t-Test
有些样本值可以成对获取,可以做Paired t-Test,一般来说效果比2-sample t-Test的更好,因为后者会包含一些各个观察间的独立变化。
定义:
One-sample t-Test
验证:
测试的统计量:
服从t分布
两个正态分布变量的总体方差是否相等
两个正态分布变量,于是服从卡方分布。
由卡方分布的定义:
我们可以得出:
F-Test
验证:
测试的统计量:
置信区间 CI公式:
多样本情况(ANOVA)
ANOVA(Analysis of Variance), 用于两个及两个以上样本均值差别的显著性检验,判断他们来自的总体均值是否相同,也是基于F-Test,不过分子和分母与上面双变量情况下有所不同。
大致意思是:
例子:
我们有a组数据,每组n个。
- 求得每组均值,然后求得这a个均值间的方差,为SST。自由度为a-1。
- 求得每组内的方差的和,为SSE。自由度为a(n-1)。
测试的统计量:
用F值与其临界值比较,推断各个样本是否来自相同的总体。
(基于假设,变量为正态分布,每组间相互独立且方差相同)