Target
Preparing Textual Data for Analysis.
Step 1: File Preprocessing
Transfer file format from HTML, Word, PDF, XML, TXT, EXCEL and etc. to format TXT, JSON or XML which can be easily import by program.
Step 2: From Text to Words
1. Tokenize
Break a stream of characters into tokens by identifying token delimiters:
- Whitespace characters such as space, tab, newline
- Punctuation characters like ( ) < > ! ? “ ”
- Othercharacters .,:‐‘’etc.

2. Lemmatization / Stemming
- Inflectional stemming: Grammatical variants of the same word (no change of POS)
- Plural form of nouns
classes -> class
stories -> story - Verbs in different tense and aspect
likes, liked, liking -> like
- Plural form of nouns
- Derivational Stemming: Forming new words from another word or stem by adding prefixes and/or suffixes (with change of POS, dangerous)
- Can change the syntactic category of a root
production -> produce - Cause a change of meaning
unhappy -> happy
- Can change the syntactic category of a root
- Other normalisation
- Case normalisation: lowercase
3. Stopword Removal
Some words are extremely common. They appear in almost all documents and carry little meaning. They are of limited use in text analytics applications.
- Functional words (conjunctions, prepositions, determiners, or pronouns) like the, of, to, and, it, etc.
- A stopword list can be constructed to exclude them from analysis.
- Depending on the domain, other words may need to be included in the stopword list.

Step 3: Indexing
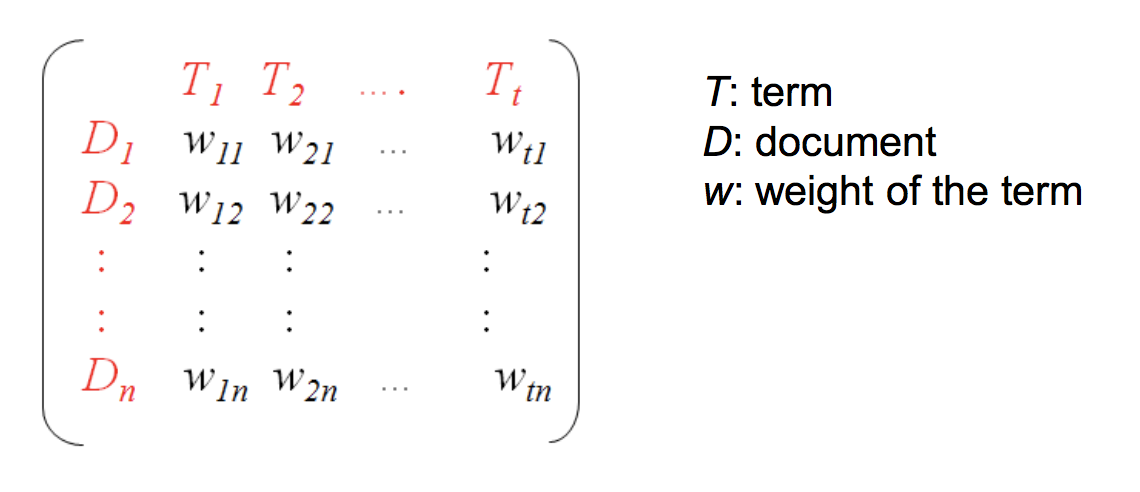
Many text mining applications are based on vector representation of documents (term‐document matrix) using “bag‐of‐words” approach.
Usually only content words (adjectives, adverbs, nouns, and verbs) are used as vector features.
- Two Ways of Term Weighting
- Binary
0 or 1, simply indicating whether a word has occurred in the document (but that’s not very helpful). - Frequency‐based*
Term frequency, the frequency of words in the document, which provides additional information that can be used to contrast with other documents.
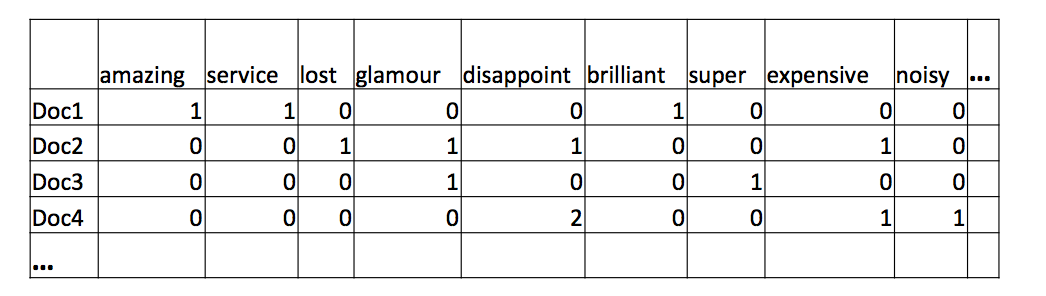
- Frequent Word List
- With frequency‐based DTM(document-term matrix), a list of words and their frequencies in the corpus can be generated.
- Sorted by frequency, can give us a rough idea of what the corpus is about.
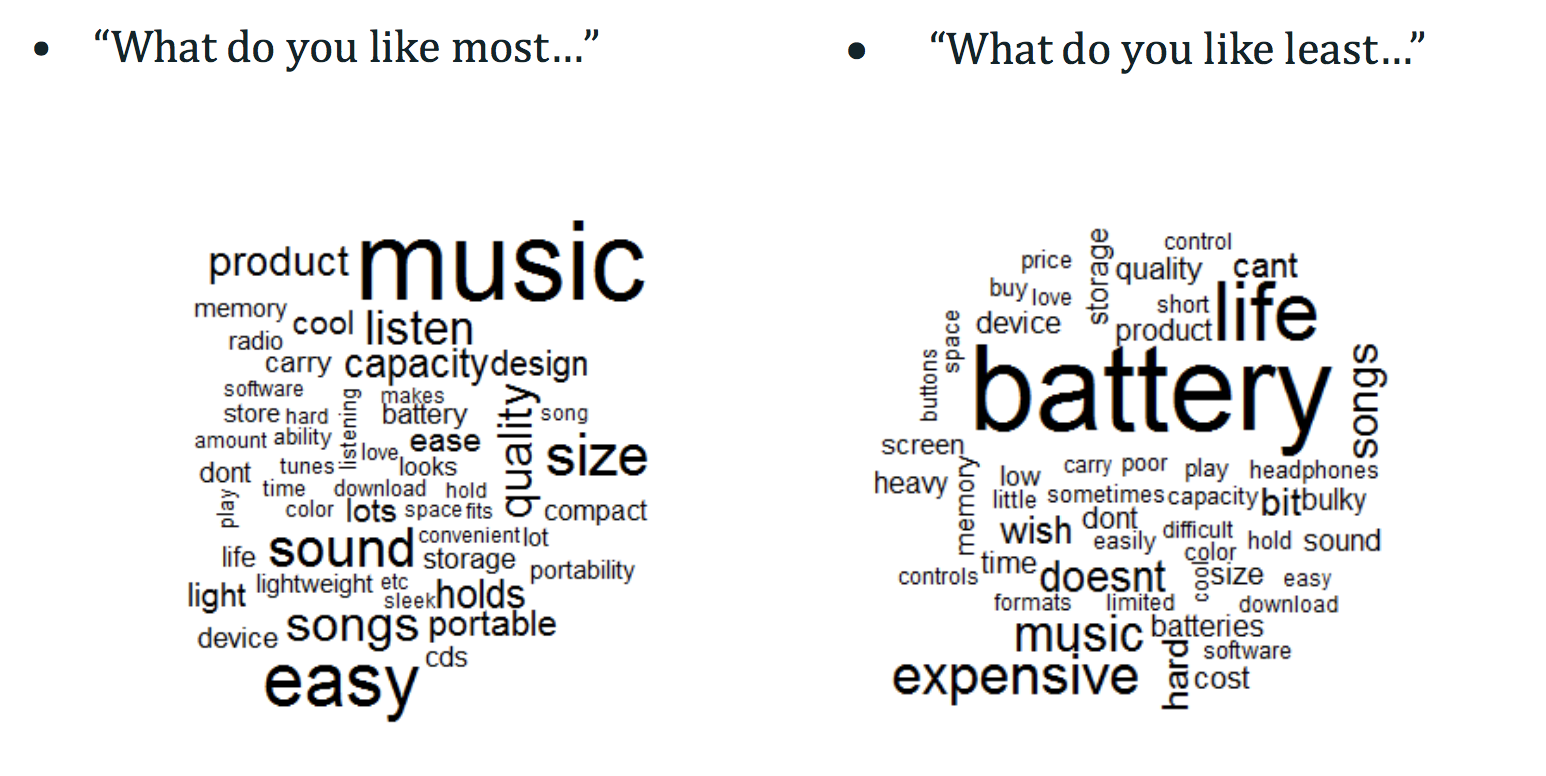
- Word Cloud is a nice visualization tool.
- Other Weighting Methods
- Normalized frequency
To deal with varied document length, since a long document definitely has more occurrences of terms than a short document.
normalized_frequency = frequency of a term in a document / total number of terms in the document - tf-idf*
To modify the frequency of a word in a document by the perceived importance of the word(the inverse document frequency), widely used in information retrieval- When a word appears in many documents, it’s considered unimportant.
- When the word is relatively unique and appears in few documents, it’s important.
- tf‐idf Indexing

Example:
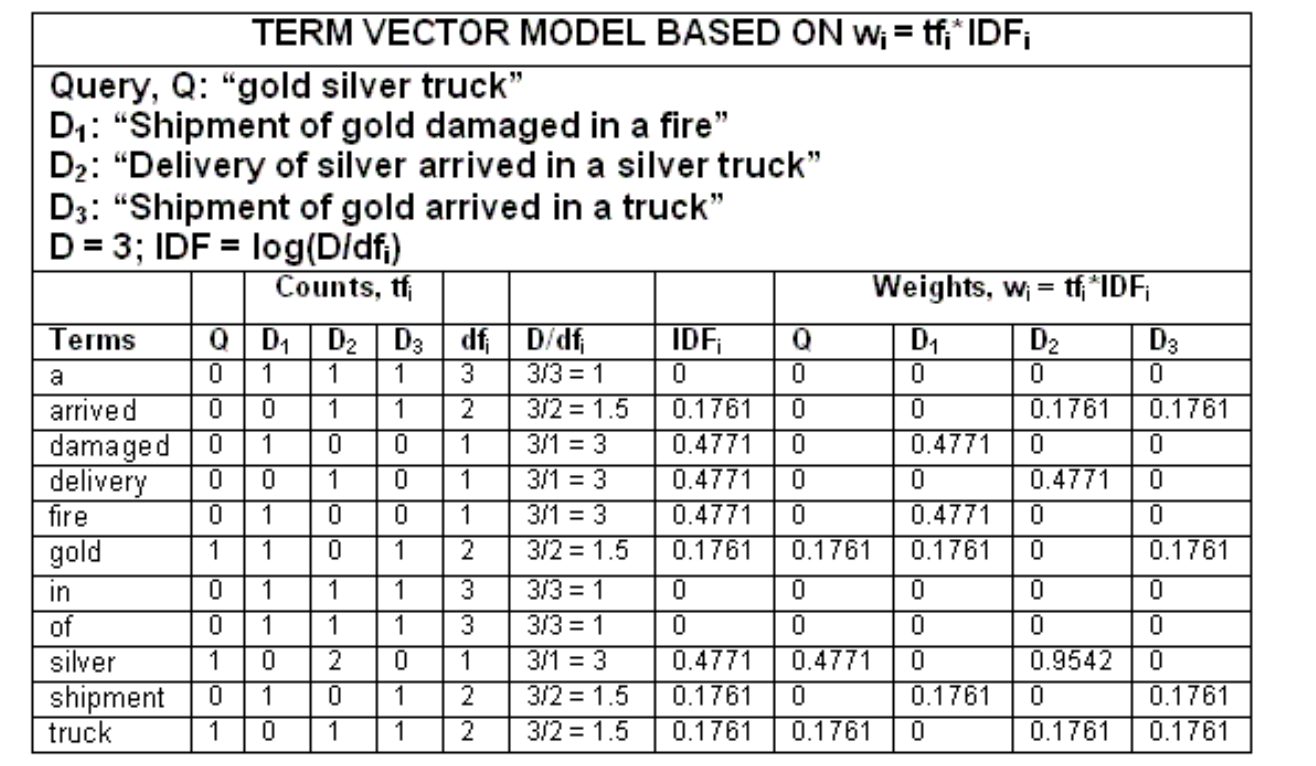
Note that in this example, stopwords and very common words are not removed, and terms are not reduced to root terms.
- Get tf table
- Calculate IDF
log(D/Df) is the log of total number of docs / the number of docs contain the term.
For term sliver:- we have three docs, so D is 3
- the number of doc contain the term sliver is one, so Df is 1
- so D/Df = 3/1 = 3
- so IDF = log(D/Df) = log(3) = 0.4771
- use TF * IDF, we get the tf-idf row value: 00.4771,20.4771,0*0.4771 is 0, 0.9542, 0
- loop this step for all terms